World2Minecraft: Occupancy-Driven Simulated Scenes Construction
Abstract
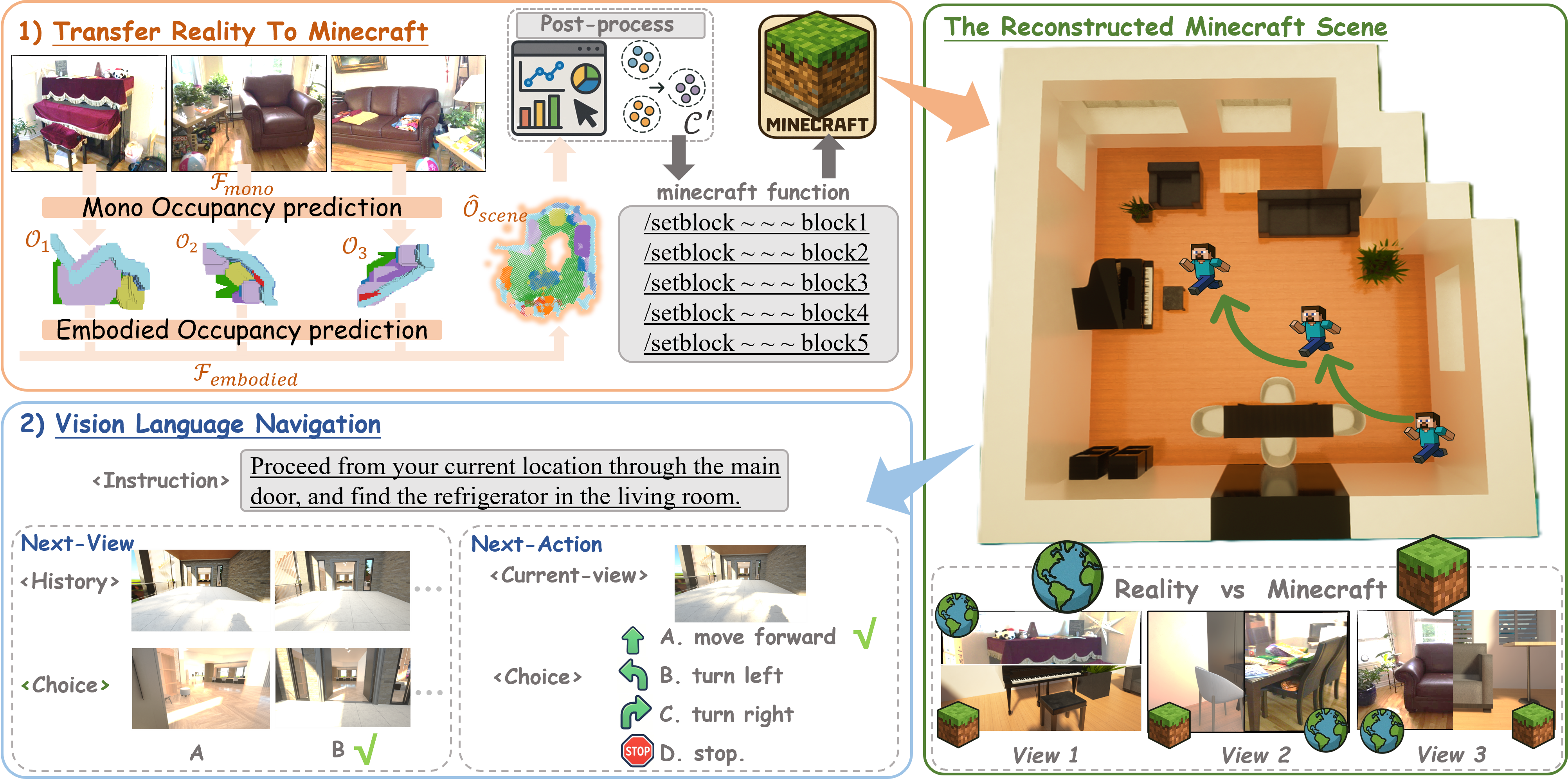
Embodied intelligence requires high-fidelity simulation environments to support perception and decision-making, yet existing platforms often suffer from data contamination and limited flexibility. To mitigate this, we propose World2Minecraft to convert real-world scenes into structured Minecraft environments based on 3D semantic occupancy prediction. In the reconstructed scenes, we can effortlessly perform downstream tasks such as Vision-Language Navigation (VLN). However, we observe that reconstruction quality heavily depends on accurate occupancy prediction, which remains limited by data scarcity and poor generalization in existing models. We introduce a low-cost, automated, and scalable data acquisition pipeline for creating customized occupancy datasets, and demonstrate its effectiveness through MinecraftOcc, a large-scale dataset featuring 100,165 images from 156 richly detailed indoor scenes. Extensive experiments show that our dataset provides a critical complement to existing datasets and poses a significant challenge to current SOTA methods. These findings contribute to improving occupancy prediction and highlight the value of World2Minecraft in providing a customizable and editable platform for personalized embodied AI research. We will publicly release the dataset and the complete generation framework to ensure reproducibility and encourage future work.
Framework
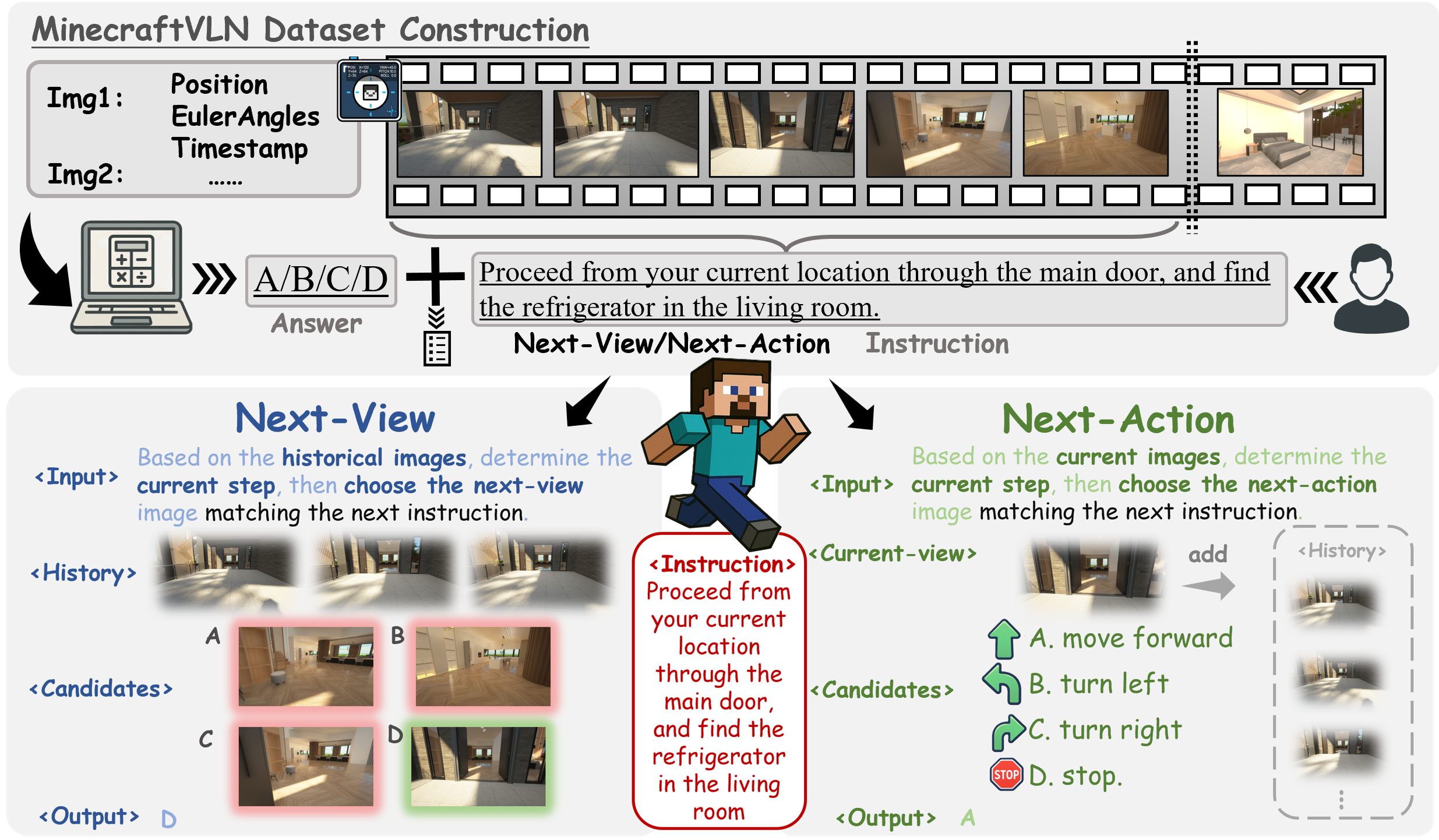
Dataset Construction for MinecraftVLN
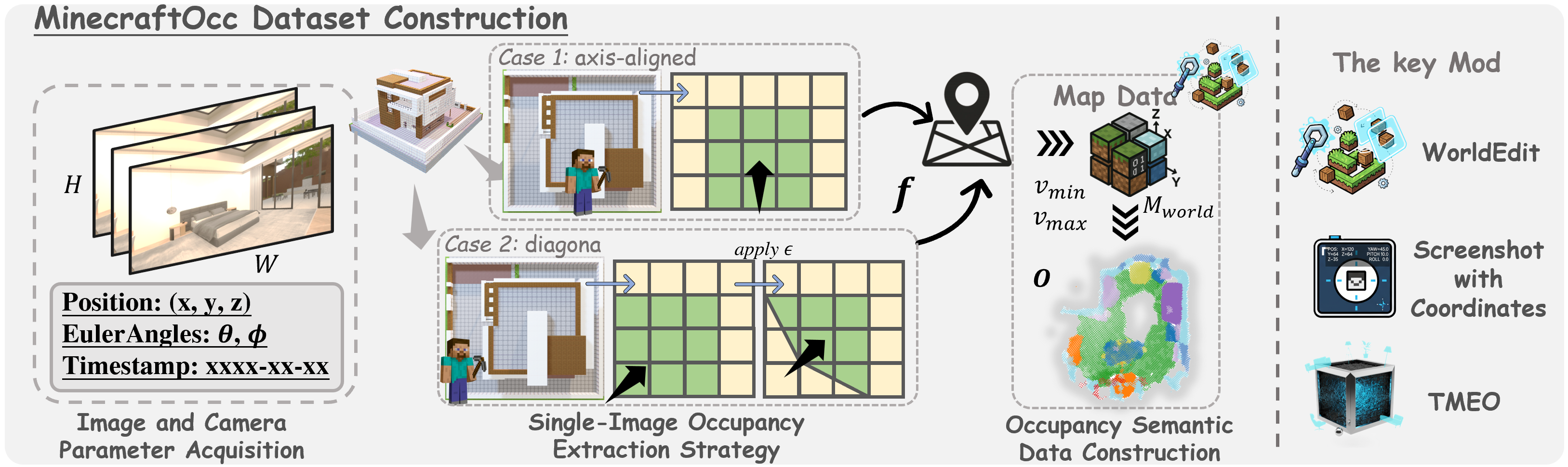
Dataset Construction for MinecraftOcc
Reconstruction Results

Demo Results

VLN Performance Results
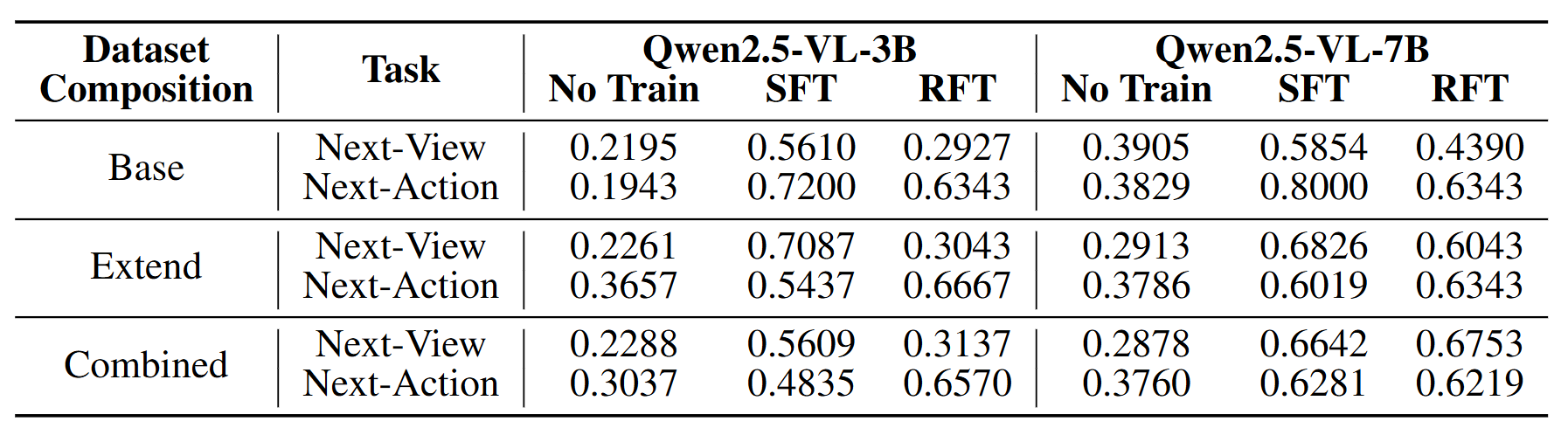
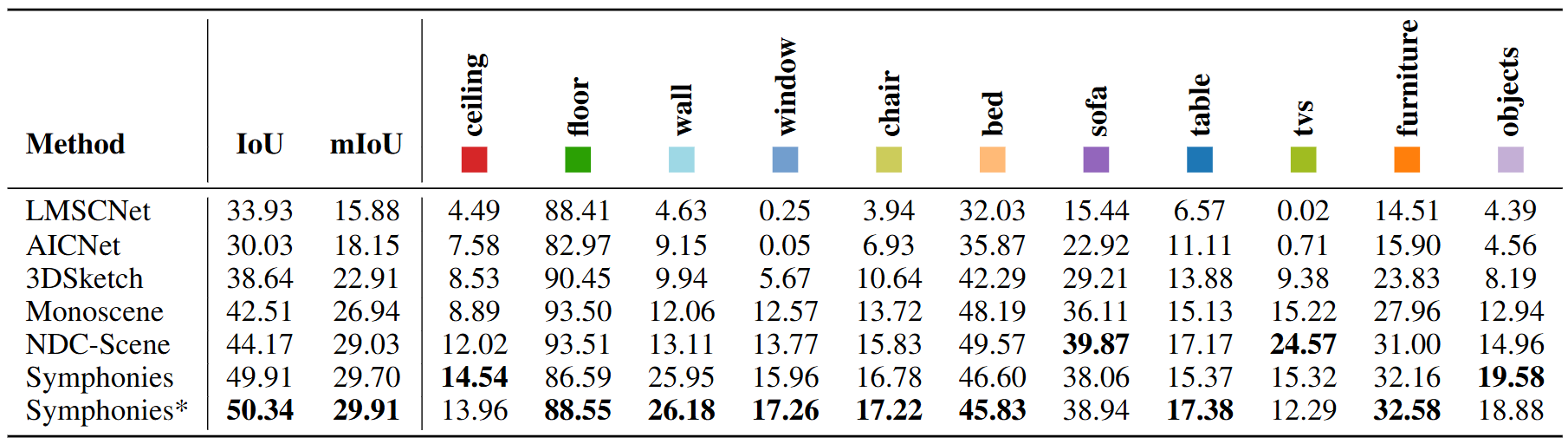
MinecraftOcc Dataset Results
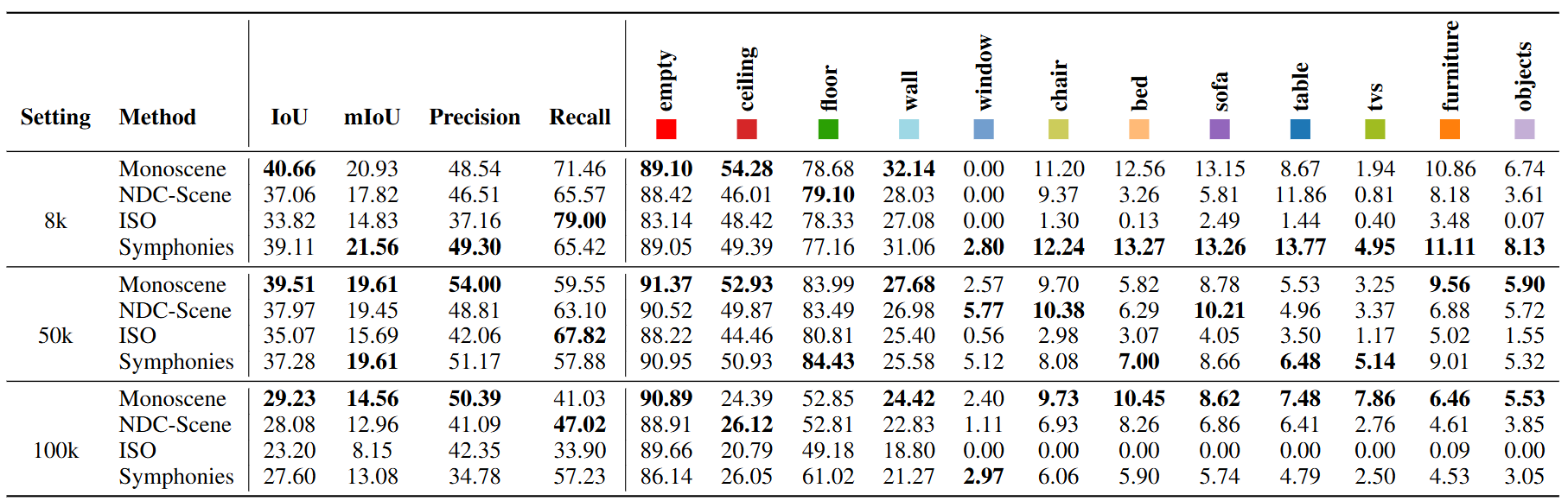
NYU V2 Dataset Performance
BibTeX
@article{zhangworld2minecraft,
title={WORLD2MINECRAFT: OCCUPANCY-DRIVEN SIMU-LATED SCENES CONSTRUCTION},
author={Zhang, Lechao and Xu, Haoran and Gong, Jingyu and Wang, Xuhong and Xie, Yuan and Tan, Xin}
}